•
•
•
•
•
•
•
•
•

Master retrieval optimization RAG techniques in 2026: smart chunking, cross-encoder re-ranking, and vector quantization to cut latency, cost, and hallucinations.

Multi-vector retrieval explained: how ColPali, late interaction, and vision RAG outperform single-vector embeddings on PDFs, charts, and complex docs in 2026.

Discover how agentic RAG combines AI agents with retrieval-augmented generation to deliver smarter, multi-step answers, better accuracy, and real autonomy in 2026.

Learn what AI embeddings are, how they turn text and images into vectors, and why they power modern search, RAG, and recommendation systems.

Compare LangChain, LlamaIndex, and Vercel AI SDK for building AI applications. Learn which framework fits your project based on RAG support, agent capabilities, streaming, and developer experience.
Compare RAG, fine-tuning, and prompt engineering for customizing LLMs. Learn when to use each approach, cost differences, and how to combine them for production AI applications.
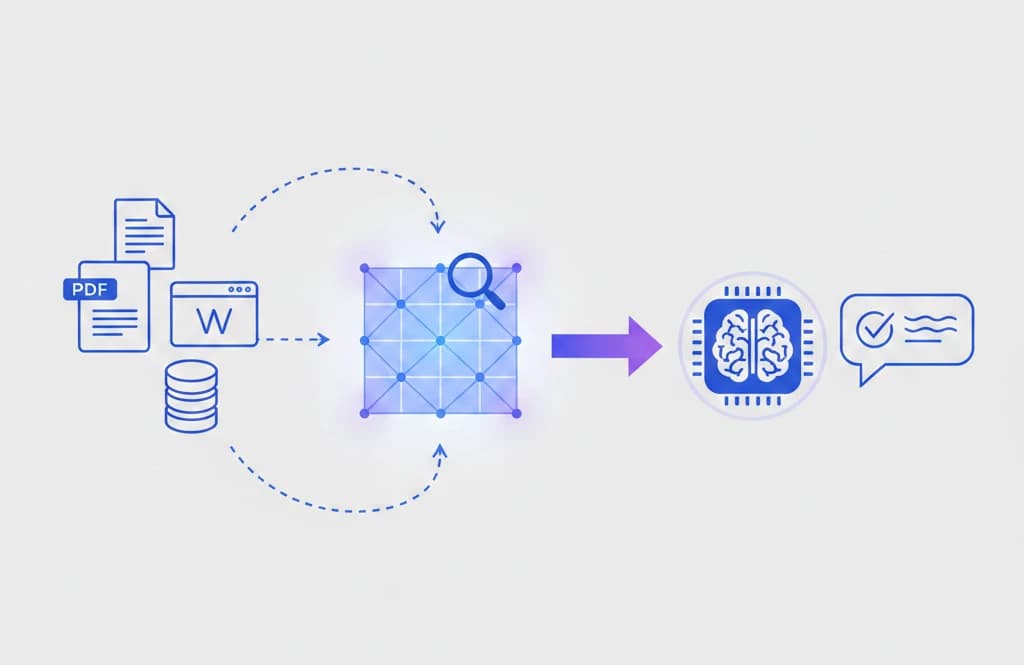
Learn what Retrieval Augmented Generation (RAG) is, how it works step by step, and why it matters for building AI applications that use your own data.

Learn how to build a production-ready RAG (Retrieval-Augmented Generation) chatbot using Next.js, Supabase with pgvector, and AI embeddings. Step-by-step tutorial for JavaScript developers.